

Extending LangFlow Components - Part I
- Apr 19, 2025
- 3 min read
Updated: Apr 25, 2025
Introduction
Welcome to the series of blogs—Extending Langflow Components, where we will share our journey of exploring and traversing through the open-source Agentic-AI development application.
Low-code platforms promise faster builds and easier automation—but often fall short with ecosystem lock-ins, limited debugging, and poor collaboration support. After testing several popular tools, we found ourselves still searching for a solution that truly fits modern AI workflows.
That’s when we discovered LangFlow—an open-source, visual tool designed to overcome these exact challenges. In this post, we share our experience with LangFlow, highlighting what worked, what didn’t, and why it’s worth your attention.

Component Rich Arsenal
LangFlow brings together a thoughtfully organized and expansive suite of pre-built components that streamline the creation of AI workflows. These components are categorized for clarity and ease of access, covering nearly every aspect of building, testing, and deploying LLM-powered solutions.
Whether you’re starting with Inputs and Outputs, crafting dynamic Prompts, handling files and documents, or orchestrating model execution through the LLMs—LangFlow offers everything you need to bring your ideas to life. Its support for Vector Stores and Embeddings enables semantic search and contextual understanding, while components like Agents, Memories, and Tools empower developers to build more intelligent, stateful applications.
Each node can be dropped into the flow editor and connected seamlessly, allowing for rapid iteration and visual clarity. This structured yet flexible approach empowers developers to prototype rapidly, test different architectures, and build scalable applications—all without writing boilerplate code. The depth and breadth of these built-in components make LangFlow a strong contender for teams working on complex AI-driven solutions.
Extending the Components
The utility of components does not end at the tasks for which they are created—you can modify existing ones or even build entirely new components from scratch.
We also got our hands dirty exploring LangFlow’s extensibility and found it refreshingly straightforward. By working directly with the component interface, we were able to inject our own logic, tailor input/output behaviors, and integrate third-party tools with minimal friction. The platform provides a well-structured foundation for customization, allowing developers to add functionality where needed without disrupting the overall workflow design.
This ability to extend and adapt components proved especially valuable when working with edge cases or non-standard requirements—situations where built-in options fell just short. LangFlow’s modular architecture allowed us to address those gaps efficiently, whether by tweaking data parsing routines, introducing custom logic gates, or connecting external services not natively supported.
The result? A more tailored, controllable development experience—one that bridges the gap between low-code convenience and full-code power.
What did we Customize?
Custom ChromaDB Filtering: While LangFlow offers native support for vector stores like ChromaDB, we needed more granular control over how documents were retrieved. To address this, we extended the component to support metadata-based filtering, enabling more precise semantic search based on document attributes.
The ChromaDB component is primarily based on Langchain’s langchain_chroma.chroma library and originally relied on its search method, which doesn't support metadata filtering. By switching to similarity_search and adding a few arguements, which does allow for metadata-based queries, we were able to introduce filtering functionality. This was made possible by adding a new input field called “Advanced Search Filter” directly into the component’s code. And just like that—voilà! The results started coming in as expected.

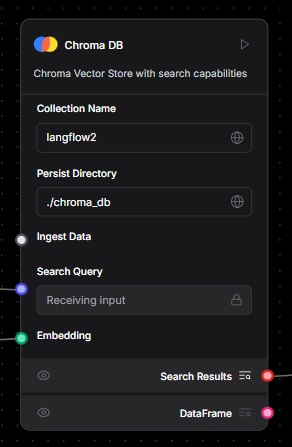

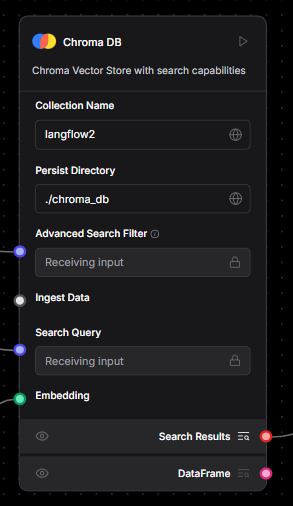
Before After
Enhanced Parser Component: For document ingestion, we built a custom parser to handle case-specific parsing of prompts. This allowed us to extract structured data and relevant context more effectively before passing it into the pipeline—improving downstream LLM performance and the metadata-based filtering from our vector store.
File Handling Enhancements: LangFlow’s default file input was useful, but we needed more flexibility when it came to outputs from the component. We developed a specialized file component that provides standalone access to file paths in output so that they can be used in other components for the purpose of indexing, retrieval, filtering etc.
Conclusion
LangFlow has proven to be more than just another visual development tool—it’s a versatile platform that strikes a balance between low-code accessibility and developer-level control. Its rich library of components, intuitive interface, and extensibility make it a strong candidate for teams building modern, agentic AI solutions.
While no tool is without its limitations, LangFlow’s open-source foundation and modular design open up endless possibilities for customization and innovation. From rapidly assembling workflows to extending components for specialized use cases, it empowers developers to move fast without compromising on flexibility.
References
LangFlow documentation: https://docs.langflow.org/
LangFlow Github Repository: https://github.com/logspace-ai/langflow
ChromaDB documentation: https://docs.trychroma.com/
Langchain Community documentation: https://python.langchain.com/docs/

Comments